项目介绍
量化投资是金融界的发展方向。 福利待遇好的行业,大家都知道是有: IT 和 金融。 而量化投资,恰恰就是这两者的交汇点。 各个金融机构,投资公司都会越来越深入地进行量化投资的领域,不可避免地就会越来越需要这方面的计算机技术人才。 而有过量化投资经历,必定在激烈的竞争中增加自己的优势。
分布式和集群开发经验。 本项目会先使用单站方式演示,然后分析其缺点,接着对这个单站基于 springcloud 进行 分布式和集群的改造。 通过参与这个过程,大家第一手资料地感受到分布式与集群的好处,积累珍贵的分布式和集群开发经验。
量化投资概念对个人理财观念的建立。 话说,你不理财,财不理你。理财是必然要做的事情,不然钱放在银行里,连通货膨胀都跑不过呢。 那么如何理财? 如何有效,低风险,高收益地理财? 通过参与这次量化投资项目,以程序员身份拉去第一手的原生资料,对原生资料,用透明的算法计算出明确的结果。 这样的方式得到的年化收益率才是让自己信服的。 可以说,量化投资观念的建立,这是一件对一生都有益的事情,而且越早开始越好呀。
投资概念
复利
复利公式:F = p* ( (1+r)^n )
F 最终收入
p 本金
r 年利率
n 存了多少年
优点
优点很明显,一只股票,每天最多可以上涨 10%。 只需要 7.2 个涨停板,就翻倍啦。
比如说现在有 10 万,最好的情况下,只要7.2天就变成 20 万啦。
缺点
缺点也一样,一只股票,每天最多可以跌掉 10%。 如果连续跌7天, 就只有原来的 47%啦。
还有更致命的是。。。 股市会爆雷和退市。 一退市,手上的股票,全成废纸了,一文不值。比如抗美,新城,乐视这几个
解决办法
既想享受股票收益带来的好处,又承受不了爆雷,退市这种巨大的风险,那么改怎么办呢?子曰: 不要把鸡蛋都放在一个篮子里。所以解决办法也简单,买很多只股票嘛。 比如说,买了100只股票,假如有一只退市了,对总体而言,亏损也才 1% 嘛,这并不是不能承受的呀。但是大家要学习,工作,生活。 哪里来那么多精力做100只股票的交易,何况还要不停地盯盘看呢? 这个时候,我们就要引入
指数的概念啦。
指数
指数是什么意思呢? 如果我买一只股票,就叫做股票投资。 如果我买很多股票,比如100只吧,而这100只股票,都是医疗方面的公司对应的股票,那么这100只股票,我们另外给它取个名字,就叫做 医疗指数。目前沪深股市里,总共有3000多家公司,如果我们把市值最大的300家公司编成一只指数,那么就叫做 沪深300指数。紧接着的 500 家公司,就叫做中证500指数
指数优点
因为一只指数里包含很多股票,所以风险就分担了,所以就不会出现像单只股票这样,退市后一下清零的问题,从安全性上来讲,就好多了。那么风险分担了,是不是收益就差很多了呢? 也不尽然, 比如以沪深300为例,其历史数据在这里可查:
http://quote.eastmoney.com/zs000300.html如图所示,在2007年这波牛市, 从最低点 807,到最高点 5891, 总共涨了有 7.29 倍。
2015年这波牛市,也是涨了有 2.3倍。当然,并不是说大家都能做到在最低的地方建仓,并且在最高的地方逃顶,而是表示指数依然是有巨大的投资潜力滴,并且它是没有退市清零的风险。除非发生极低概率的事情,比如第三次世界大战
指数缺点
与普通股票一样,指数也会发生大起大落。它也是非常具备波动性的。 那么如何多赚上涨钱, 而少吃下跌的亏呢? 这就是本项目: 量化趋势投资要解决的问题啦。
那么指数又如何交易呢? 实际指数身是没有办法进行交易的,我们只能交易指数基金。 这就是接下来的知识点要讲的啦: 指数基金
基金
基金说白了,就是一下子买卖一揽子股票。 这样交易起来就轻松愉快多了,而不用那么繁琐切容易出错了。
主动基金
基金可以简单地分为主动基金和被动基金。基金主要是由基金经理进行打理,主动基金就是由基金经理决定,对那些股票进行交易,什么时候交易,交易多少。所以基金经理本人的见识,理念,执行力以及与当时的行情契合程度,就决定了基金的收益如何。
好的主动基金的收益是非常可观的。 同样的,差的主动基金,也是差的很让人吐血的。
http://fund.eastmoney.com/data/fundranking.html#tall;c0;r;szzf;pn50;ddesc;qsd20180716;qed20190716;qdii;zq;gg;gzbd;gzfs;bbzt;sfbb这里就是东方财务的天天基金网提供的各个基金排行榜。 可以看到主动基金的收益高的是很高滴,低的也是很低滴。那么谁能保证自己一定能买到收益最高的那个呢? 这个和在茫茫股海里选股,选到好的主动基金的概率似乎也不太乐观呢。
被动基金
所谓的被动基金,就是跟踪指数的基金。 指数是由多个股票组成,比如 沪深300指数,就是由市值最大的300只股票,按照一定的比例进行组合而成。
而跟踪指数300的基金,可以说,就是尽量无脑和 沪深300指数里的股票指数尽可能的保持一致。这样,就和基金经理本人的能力,见识,执行力什么的不可控的元素脱钩了。
比如说沪深300,在天天基金上搜索,就可以看到各个不同的基金公司对 300的跟踪基金。 他们的表现会有一定的出入,但是差别都不太大。
被动基金收益
那么被动基金的收益到底如何呢?
我们还是以沪深300为例,我们选博时沪深300指数基金为例来进行分析:http://fund.eastmoney.com/050002.html?spm=search
如图所示,它成立于2003年,到现在累计净值达到了 3.4822. 期间总共经历了 16年的时间。
累计净值 3.4822 是什么概念呢? 就是说, 假如从 2003年,就投入了一笔钱,比如说 10000块吧,到今天就是 34822 元了。
经历了16年,那么年化是多少呢:3.4822 ^ (1/16) = 1.08
它的年化达到了惊人的 8%。
没想到吧,买一指数基金,就算什么都不做,平均算下来,每年都有 8%的收益。 这可比存银行每年的利息高多了。 且不说低的可怜的活期了,就算是大额存单,才 4.2% 左右。
其实指数基金的年化收益已经挺不错了,那么如何再提高呢? 这就是下个知识点我们要讲的量化投资啦: 量化投资
传统投资VS量化投资
传统投资:就像是中医,靠的是经验,见识,个人判断。 有时候能够取得非常耀眼的成绩,但是与此同时,也会因为一步错迈向无底深渊呀。
量化投资:就像是西医,靠的是系统,数据,统计概率。 掌握了一定的量化手段,不需要具备20年的从业经验,也会在证卷市场取得相当的成绩。 虽然不能像传统投资里的某些神人那样,取得非常辉煌的战绩,但是超越普通人的投资汇报,还是可以期待的。
量化技术
量化技术有很多种,如高频交易,价值投资,定投, 网格,趋势投资,alpha 投资 等等等等。
不同的技术,都会要求不同的策略,对与不同市场的收益也各不相同。而量化投资技术本身已经发展地相对成熟了,就如同大家用 java 来开发网站一样,会有各种设计模式, mvc 结构, 前后端分离等等现成的套路。 量化投资也是一样,有很多前人的研究成果,大家可以直接拿来用就是了,不一定需要自己全部从0来研究。
趋势投资
What?
所谓的趋势投资,就是认为凡事都有一定的惯性。 比如基金上涨到一定程度形成了趋势,有一定的概率后面还是会上涨。同样的,下跌的趋势一旦形成了,也有一定的概率后面还是继续下跌。
所以趋势投资其实就是等待两种信号,当上涨趋势形成,就会得到一个买入信号,此时就进行买入。 当跌倒一定程度了,就会得到一个卖出信号,就进行卖出操作。
说白了,就是追涨杀跌。哈哈,可是一听到追涨杀跌这4个字,是不是就有一种被割韭菜的感觉呢? 那么为什么趋势投资的追涨杀跌可以盈利呢? 下个步骤,就来讲为什么可以盈利。
Why?
既然是趋势投资是追涨杀跌,为何能盈利呢?
知乎上有一篇文章讲的非常好: https://www.zhihu.com/question/56722334/answer/522204836
简单概括一下:
交易的交易盈亏概率就是这个正态分布图。 大部分交易都是 -0.025% 到 0.025% 之间,就是输赢都不大,但是了占绝了大部分的比例。
赢很多的,就是右边的,但是他们很少。
输很多的,就是左边的,同样的,他们也很少。
趋势投资为什么能盈利? 因为按照趋势投资的算法,它会保留绝大部分右边的,但是却会砍掉绝大部分左边的。 总体上来讲,盈利的大部分都吃掉了,而亏损的大部分都躲避了。 所以,最后就会有不错的盈利表现了。
SO
那么做趋势投资是不是只赚亏呢? 哈哈哈,这世界,哪里来只赚不亏的生意呀, 肯定也是会亏的嘛。 只是亏得幅度更小。趋势投资的特点是: 当大盘上涨的时候, 涨得会少一些。 当大盘跌的时候,跌得也更少一些。
分布式和集群
单体架构
家里生小宝宝啦,由于自己没有照顾小宝宝的经验,所以请了位经验丰富的月嫂。 这位月嫂从买菜,到做饭,洗衣,拖地,喂奶,哄睡,洗澡,换纸尿裤,擦屁股,做排气操,夜间陪护,给奶妈做月子餐等等,全部都做。 这种叫做单体架构。
集群:
什么都做,一个月嫂怎么够呢,肯定忙不过来呀,那就请两个月嫂吧,这叫做集群。
高可用概念:
有一个月嫂过生日,想请假回去和亲戚打一天麻将。如果只有一个月嫂,她走了,就叫做服务中断了。 但是因为做了集群,有两个月嫂,走了一个,另一个还是能用,虽然相比较吃力一些,但是毕竟还是能用的,这个现象叫做高可用。
分布式:
一个月嫂,一个月的费用基本上都要1万多,还有房贷,还有车贷,生活费用还高,实在是请不起两位啊,那就还是请一位吧。 可是事情那么多,她实在忙不过来,怎么办呢? 那就把爷爷请过来买菜,把奶奶请过来做饭。 这样服务本来仅仅是由月嫂一人提供的,变成了和宝宝相关的由月嫂负责,采购由爷爷负责,餐饮由奶奶负责。 这就叫做分布式了。
低耦合概念:
做宝宝服务的月嫂去打麻将了,不影响做饭的奶奶。 做采购的爷爷去喝酒了,也不影响月嫂的宝宝服务,这叫做低耦合。
高内聚概念:
和宝宝相关的事情都是月嫂在做,月嫂兑奶方式快慢,只会影响自己,对爷爷和奶奶的服务没影响. 这叫做高内聚。
集群+分布式:
奶奶一个人做饭,做久了也烦啊,也累啊,也想打麻将呀。 那么就把姥姥也请过来吧。 这样做饭这个服务,就由奶奶和姥姥这个集群来承担啦。她们俩,谁想去汗蒸了,都有另一位继续提供做饭服务。 这就叫做集群+分布式。
服务注册中心
我这里使用Alibaba的nacos作为注册中心
- 默认控制台地址: http://localhost:8848/nacos/index.html
第三方数据
使用各类指数数据,以json格式存储
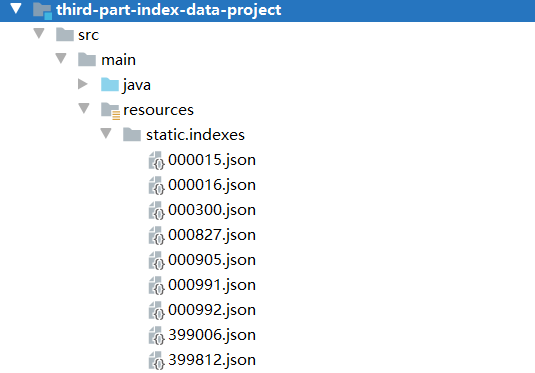
其中date 表示成交日, closePoint 表示收盘价。
注: 从真正的第三方拿到的数据结构会更复杂,比如会带上 pb,pe 等等各式各样的金融指标。
采集和存储服务
第三方数据服务 的数据其实是存放在第三方的,今天能访问,明天或许就不能访问了,所以我们就需要把它采集下来,并且存储在本地。
采集使用的是 RestTemplate 方式来做, 存储本地我们会采用 redis 来保存。
service层:将Json数据取回是Map对象,需要专为pojo对象
1 |
|
断路器
我这里使用Sentinel作为断路器,并使用注解定义资源
具体的注解参数参照@SentinelResource 注解
引入Sentinel的POM
1 | <dependency> |
首先启动Sentinel的dashboard,注意指定端口
1 | java -Dserver.port=8088 -jar sentinel-dashboard-1.3.0.jar |
对目标服务添加注解,这里有个坑,必须添加value才能使用,并且保证fallback函数的输入输出参数完全一致
1 | (value = "fetchIndexesFromThirdPart", fallback = "fallBackMethod") //降级策略 |
采集和存储Redis
使用Win版Redis,使得加载一次数据后,后面可以从redis获取数据
POM添加Redis支持
1 | <!-- redis --> |
启动类开启缓存注解
增加 @EnableCaching 表示启动缓存
Service层增加注解
增加 @CacheConfig(cacheNames="indexes") 表示缓存的名称是 indexes.
在fetch_indexes_from_third_part 方法上增加: @Cacheable(key="'all_codes'") 表示保存到 redis 用的 key 就会使 all_codes.(注意双引号里面的单引号)
what fuck,被墙了?
Redis刷新
如果第三方能用,就把数据放在 redis里了。如果第三方不能用,就把断路数据放在 redis 里了。
以后无论第三方是否有变化, 因为 redis 里面已经有数据了,所以下一次访问,以及以后的所有访问都会从 redis 里获取数据了。 这就带来了数据无法刷新的问题。
刷新的思路就是:
- 先运行 fetch_indexes_from_third_part 来获取数据
- 删除上一次
redis的数据 - 保存新的数据数据
- 从而达到刷新的效果
增加
util.SpringContextUtil类
1 | package com.tosang.springcloud.util; |
改造
IndexService类
1 | /** |
控制层
1 | /** |
说明:Spring AOP无法拦截内部的方法调用,所以无法执行一系列拦截代理操作。换言之,实际调用的是this.remove,而不是proxy.remove,Spring的注解处理器就无法生效,但是通过代理方法获得类的方式时就可以正确的执行注解处理器的操作。
关于spring 缓存中@Cacheable、@CachePut和@CacheEvict介绍 以及#p0的含义,参照
https://blog.csdn.net/qq_29663071/article/details/81511845
采集和存储指数数据
和指数名称的采集类似,稍作修改即可。
定时器
第三方的数据一般说来每天都会更新。 按照前面的做法,需要访问 fresh 地址才能实现刷新的效果,难道每天都自己手动去刷新吗? 这也很繁琐嘛,何况很有可能会忘记。
所以我们就引入定时器工具 Quartz 来解决这个问题吧
关于Quartz的使用参照:https://how2j.cn/k/quartz/quartz-start/1707.html#nowhere
编写任务Job
1 | /** |
配置类
1 | /** |
这里设计为1分钟执行一次任务
指数代码微服务
为什么不直接用采集和存储服务提供呢? 采集和存储服务已经提供了web接口, 干嘛要专门提供一个微服务来获取指数代码?
原因有两个:
- 采集和存储服务本身定位是在采集和存储服务上,其提供的web接口只是为了调试用,其定位不是用于提供指数数据的。
- 为了使用集群,指数代码微服务会有多个, 而采集和存储服务并非不能做集群,但是它里面有定时器,如果也做成集群,就会有多个定时器同时工作,一起向第三方获取数据,一起把数据保存到 redis里。 这样不仅是额外的开销,也埋下了出现数据冲突的风险。
所以会专门有一个微服务来单纯地提供指数代码。
什么是跨域请求:https://www.jianshu.com/p/a15bb79bffb0
流程:index-codes-service服务 请求redis服务 <—–> redis(由采集和存储服务添加)
1 | //集群 http://127.0.0.1:9011/codes |
指数数据微服务
思路同指数代码微服务
网关
通常我们如果有一个服务,会部署到多台服务器上,这些微服务如果都暴露给客户,是非常难以管理的,我们系统需要有一个唯一的出口,API网关是一个服务,是系统的唯一出口。API网关封装了系统内部的微服务,为客户端提供一个定制的API。客户端只需要调用网关接口,就可以调用到实际的微服务,实际的服务对客户不可见,并且容易扩展服务。
API网关可以结合ribbon完成负载均衡的功能,可以自动检查微服务的状况,及时剔除或者加入某个微服务到可用服务列表。此外网关可以完成权限检查、限流、统计等功能。下面我们将一一完成上面的功能。注意微服务只是提供rest的接口,不会有额外的组件依赖,不需要eureka等。只需要两个工程,一个是微服务,我们可以部署到多台服务器,那么只是访问的ip不同,在演示的时候,我们在本机演示,修改端口,达到启动多个微服务的目的,另一个就是网关,主要是spring cloud gateway 和 ribbon两大组件来实现网关和负载均衡等功能(参考)
首先引入所需依赖
1 | <dependencies> |
YML配置
1 | spring: |
网关测试测试:http://127.0.0.1:8031/api-codes/codes 。默认采用轮询算法
模拟回测服务
在模拟回测视图那里需要很多的数据,这些数据都是从这个模拟回测服务里产生的。 虽然现在看上去只有单纯的指数原数据,但是随着业务的增加,功能的迭代,会有越来越丰富的数据产生出来啦。
在这个模块中新增了
openfeign,替代rest Template使用。
1 | <dependency> |
开启feign模式的断路器
1 | spring: |
将回测添加入网关
模拟回测视图
视图:http://127.0.0.1:8031/api-view/
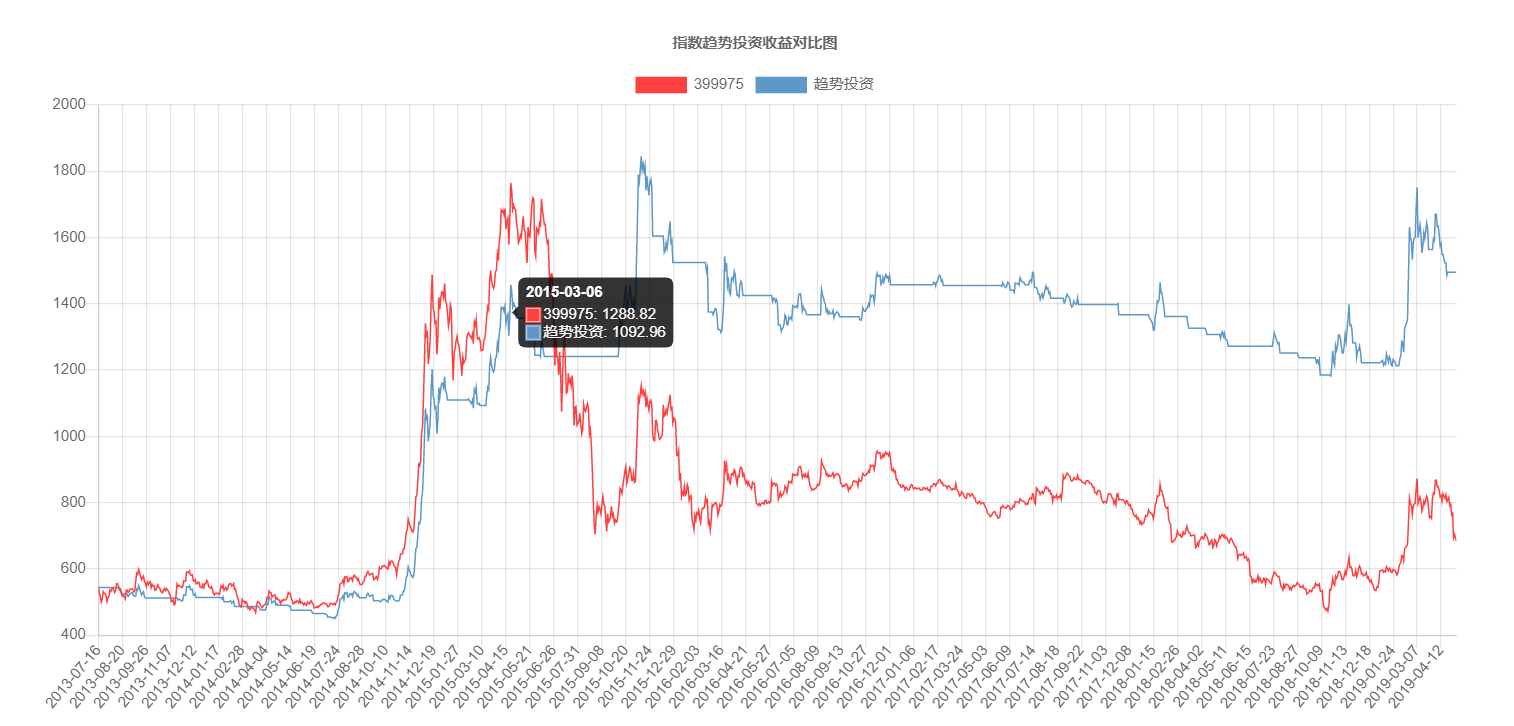
趋势投资收益
接下来,我们就要在当前指数数据的基础上做趋势投资的模拟回测了。
趋势投资为什么能盈利,我们在 趋势投资 里分析过了,如图所示,它其实就是砍掉了左边重大损失不部分,保留了右侧重大收益部分,所以盈利了。 为了做到这一点,我们需要建立两个概念: MA 均线,和出售阈值。
MA 均线:MA 即 moving average, 移动均线的意思。 比如MA20就表示20日均线,取最近20天的值的平均数。 如果当前的收盘点高于这个均线一定的比例,那么我们认为上涨的趋势可能就来了,就可以买了。
出售阈值:如果当前的收盘点,比起最近的20个交易日里的最高的点,跌了 5%或者 10%了,那么我们认为下跌趋势可能就来了,就可以卖了。
采用这种思路,就可以增加获取右边高收益的几率,降低左边吃大亏的几率。 随着次数的累计,总收益就会不错啦。
ma—–均线日期
sellRate—出售阈值,按百分比计算。
buyRate—购买阈值
serviceCharge—服务费用
1 | public Map<String,Object> simulate(int ma, float sellRate, float buyRate, float serviceCharge, List<IndexData> indexDatas) { |
链路追踪
Spring Cloud Sleuth是对Zipkin的一个封装,对于Span、Trace等信息的生成、接入HTTP Request,以及向Zipkin Server发送采集信息等全部自动完成。这是Spring Cloud Sleuth的概念图
所以只需要引入zipkin的依赖就可以
1 | <!--zipkin--> |
之后在yml添加相应配置即可开启链路追踪,使用zipkin的server控制台可以查看链路
配置服务器
这里使用nacos作为配置服务器
总结
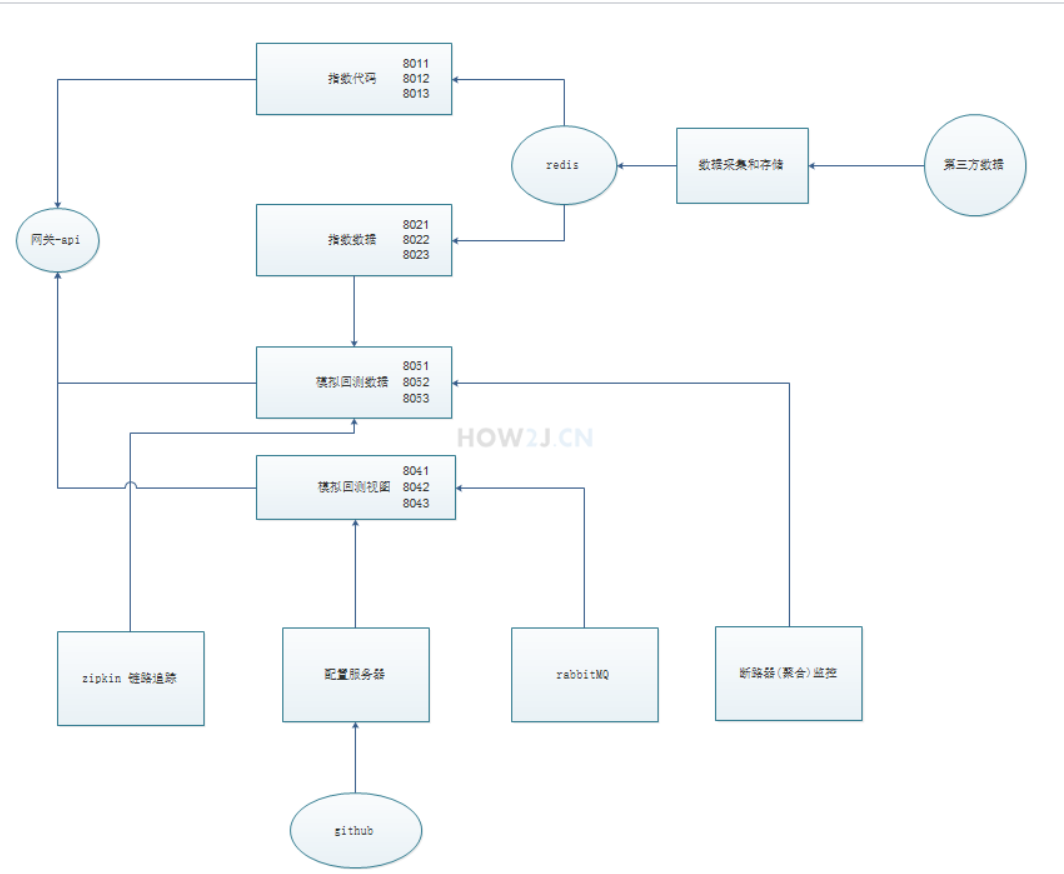
项目架构图
技术栈
为了完成这个项目,都用到了以下的技术
- Java
Java基础 和 Java中级 的大部分内容 - 前端
html, CSS, Javascript, JSON, AJAX, JQuery ,Bootstrap, Vue.js ,chartjs - 框架部分
spring springmvc springbootSpringCloudAlibaba(nacos、sentinel、feign、zipkin) - 中间件
redis - 开发工具
Intellij IDEA,Maven - 分布式
SpringCloud