小y的SpringCloud学习总结 :sunny:
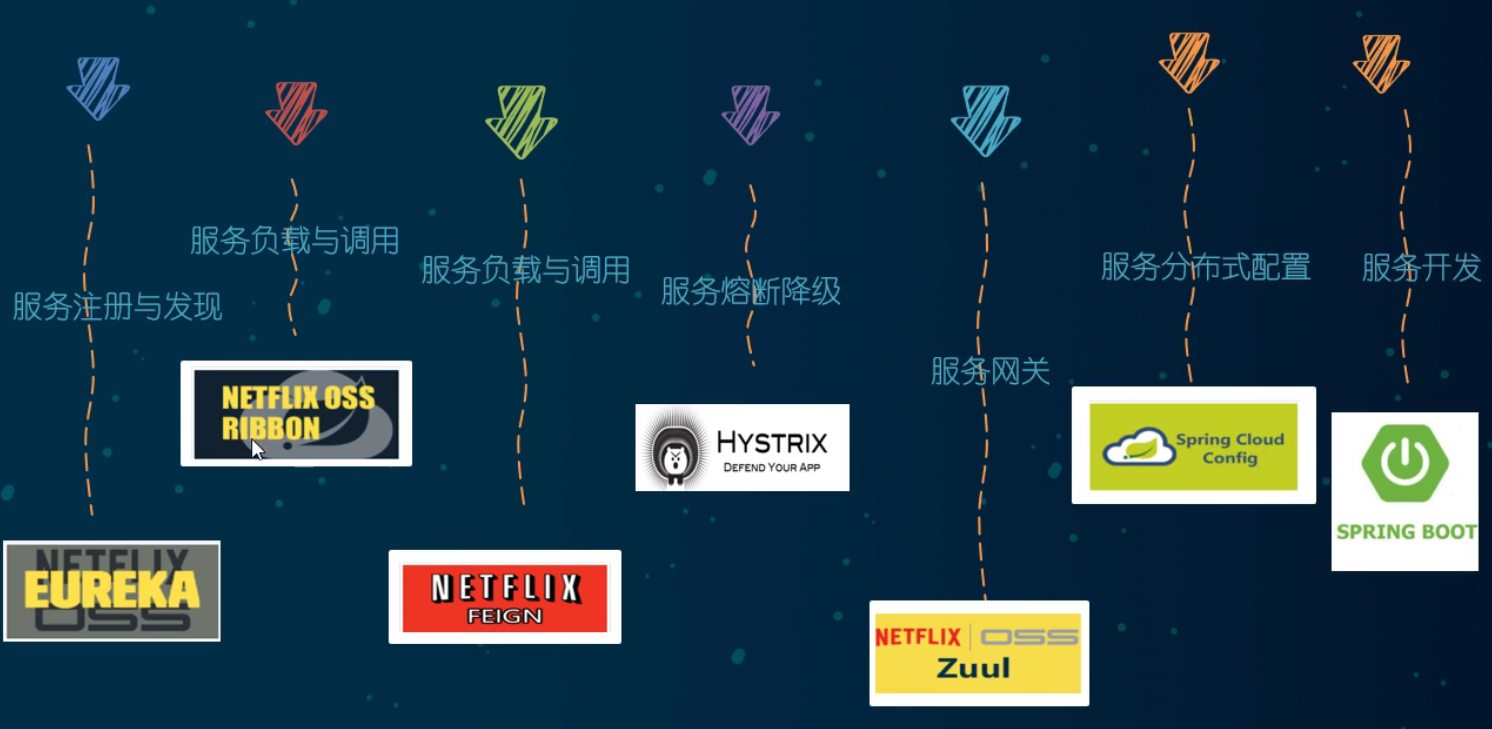
SpringCloud介绍
![image-20200622113343410]()
- 版本选型
SpringBoot 2.2.x 2.2.2.RELEASESpringCloud Hoxton版 Hoxton SR1cloud alibaba 2.1.0.RELEASEJava Java8Maven 3.5以上MySQL 5.7以上
Cloud组件停更说明
服务注册中心:
Eureka:x:已经不再更新Zookeeper 缺乏管理面板,使用起来不方便Nacos 现在最常用的注册中心:heavy_check_mark:
服务调用:
Ribbon 后续会可能弃用LoadBalance 新推出的服务调用框架Feign :x:已经弃用OpenFeign Spring社区自己推出的服务调用组件:heavy_check_mark:
服务降级:
Hystrix 已经弃用:x:resilience4j 国外推荐用来替换Hystrix的框架sentienl 阿里新推出的:heavy_check_mark:
服务网关:
Zuul 因为分歧而停更:x:gatewayspring推荐的组件:heavy_check_mark:
服务配置:
Config:x:Nacos :heavy_check_mark:
服务总线
Bus :x:Nacos :heavy_check_mark:
创建工程
POM文件配置,以下是父工程的pom文件内容
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
|
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>12</maven.compiler.source>
<maven.compiler.target>12</maven.compiler.target>
<junit.version>4.12</junit.version>
<lombok.version>1.18.10</lombok.version>
<log4j.version>1.2.17</log4j.version>
<mysql.version>8.0.18</mysql.version>
<druid.version>1.1.16</druid.version>
<mybatis.spring.boot.version>2.1.1</mybatis.spring.boot.version>
</properties>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-project-info-reports-plugin</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>2.2.2.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>Hoxton.SR1</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-dependencies</artifactId>
<version>2.1.0.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysql.version}</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>${druid.version}</version>
</dependency>
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
<version>${mybatis.spring.boot.version}</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>${junit.version}</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>${log4j.version}</version>
</dependency>
</dependencies>
</dependencyManagement>
|
区别dependencyManagement和dependencies
Maven使用dependencyManagement元素来提供了一种管理依赖版本号的方式。通常会在一个组织或者项目的最顶层的父POM中看到dependencyManagement元素。使用pom.xml中的dependencyManagement元素能让所有在子项目中引用一个依赖而不用显式的列出版本号。Maven会沿着父子层次向上走,直到找到一个拥有dependencyManagement 元素的项目,然后它就会使用这个dependencyManagement元素中指定的版本号。
:star:dependencyManagement只是声明依赖,并不实现引入,因此子项目需要显示的声明需要用的依赖。如果不在子项目中声明依赖,是不会从父项目中继承下来的;只有在子项目中写了该依赖项,并且没有指定具体版本,才会从父项目中继承该项,并且version和scope都读取自父pom;如果子项目中指定了版本号,那么会使用子项目中指定的jar版本。
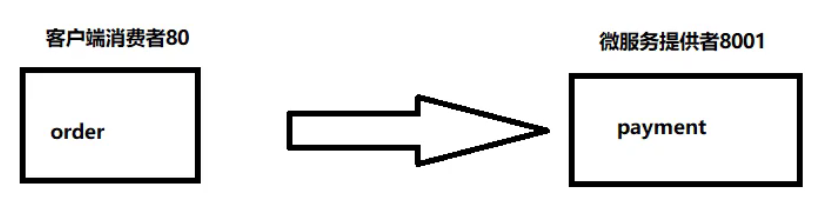
支付模块构建
需要构建如下图所示的模块
![image-20200622162958934]()
微服务模块构建流程:
- 建module
- 改POM
- 写YML
- 主启动
- 业务类
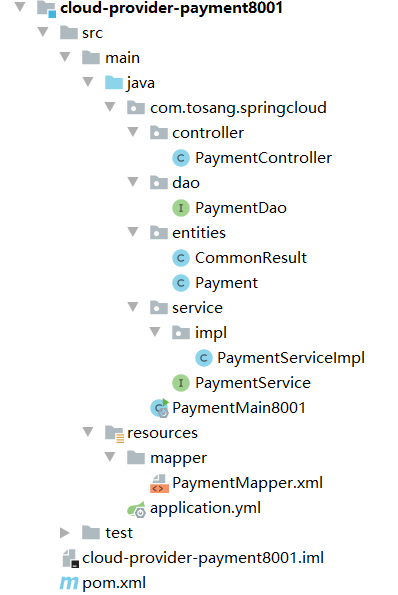
提供者模块:cloud-provider-payment8001
POM文件如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| <dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>org.mybatis.spring.boot</groupId>
<artifactId>mybatis-spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.10</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-autoconfigure</artifactId>
<version>2.2.2.RELEASE</version>
</dependency>
</dependencies>
|
application.yml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| server:
port: 8001
spring:
application:
name: cloud-payment-service
datasource:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.alibaba.druid.proxy.DruidDriver
url: jdbc:mysql://localhost:3306/db2019?useUnicode=true&characterEncoding=utf-8&useSSL=false
username: root
password: 123456
mybatis:
mapperLocations: classpath:mapper/*.xml
type-aliases-package: com.tosang.springcloud.entities
|
启动类
1
2
3
4
5
6
7
8
9
10
11
12
| package com.tosang.springcloud;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class PaymentMain8001 {
public static void main(String[] args) {
SpringApplication.run(PaymentMain8001.class, args);
}
}
|
业务类——SQL
1
2
3
4
5
6
7
|
CREATE TABLE `payment`(
`id` BIGINT(20) NOT NULL AUTO_INCREMENT COMMENT 'ID',
`serial` VARCHAR(200) DEFAULT '',
PRIMARY KEY(`id`)
)ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8
|
controller,dao,entities,service,mapper各层目录结构如下
![image-20200708082150124]()
注意:子模块可能无法调用父模块的依赖(由于maven在IDEA2020下的抽风),尤其是可以尝试手动添加mysql-connector-java的maven依赖,并且需要注意驱动版本和mysql匹配以及mysql的ssh是否关闭。
消费者模块:cloud-consumer-order80
restTemplate
1
2
3
|
return restTemplate.postForObject(PAYMENT_URL+
"/payment/create", payment, CommonResult.class);
|
Adding devtools to your 子模块project
1
2
3
4
5
6
| <dependency>
<groupId>org.springframework.boot</ groupId>
<artifactId> spring-boot-devtools</artifactId>
< scope>runtime</scope>
<optional>true</optional>
</dependency>
|
Adding plugin to your 父工程pom.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
| <build>
<finalName>你自己的工程名字</finalName>
<plugins>
<plugin>
<groupId>org.springframework.boot</ groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<fork>true</fork>
<addResources>true</addResources>|
</configuration>
</plugin>
</plugins>
</build>
|
Enabling automatic build
Update the value of
不过开启热部署,性能耗费会较大,不建议使用
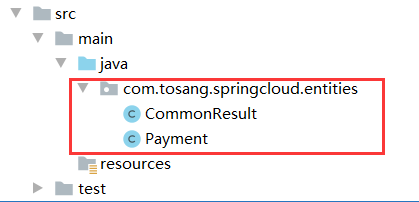
项目重构
实体类在子模块都是重用的,需要抽取出来作为公共类
![image-20200710092249034]()
MAVEN打包
这个地方是个大坑,建议如下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
| #首先添加阿里云镜像,这一步相信大家都会
(但是建议是先运行一次官方版本maven保证下载了maven插件再替换镜像,这取决于你的网络,很可能并不会一定成功)
<mirror>
<id>aliyunmaven</id>
<mirrorOf>*</mirrorOf>
<name>阿里云公共仓库</name>
<url>https://maven.aliyun.com/repository/public</url>
</mirror>
#如果继续爆红,尝试指定java版本,这点非常关键
<profile>
<id>jdk-1.8</id>
<activation>
<activeByDefault>true</activeByDefault>
<jdk>1.8</jdk>
</activation>
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<maven.compiler.compilerVersion>1.8</maven.compiler.compilerVersion>
</properties>
</profile>
# maven插件抽风爆红困扰了我很久,指定java版本经我检测是很有效的办法
|
一切就绪点击maven install即可
导包
1
2
3
4
5
6
|
<dependency>
<groupId>org.tosang</groupId>
<artifactId>cloud-api-commons</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
|
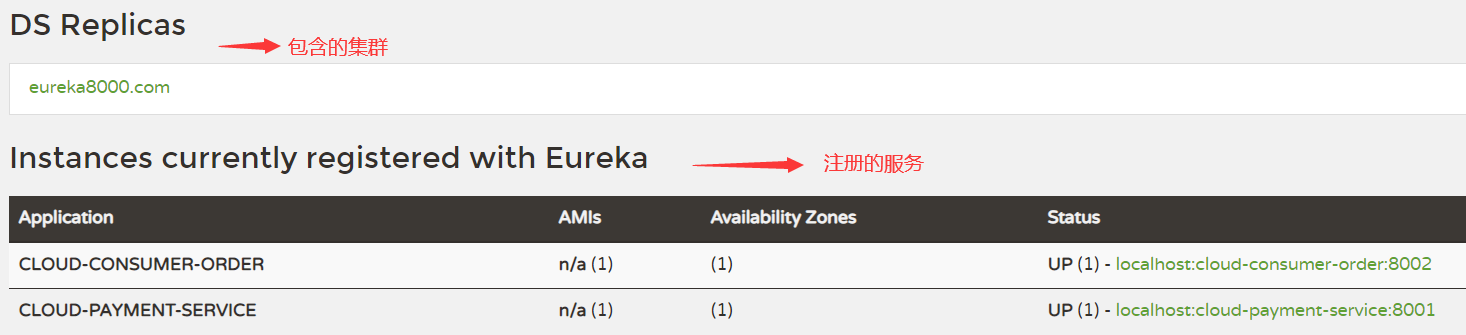
Eureka服务注册与发现
Eureka采用了CS的设计架构,Eureka Server作为服务注册功能的服务器,它是服务注册中心。而系统中的其他微服务,使用Eureka的客户端连接到Eureka Server并维持心跳连接。这样系统的维护人员就可以通过Eureka Server来监控系统中各个微服务是否正常运行。在服务注册与发现中,有一个注册中心。 当服务器启动的时候,会把当前自己服务器的信息比如服务地址通讯地址等以别名方式注册到注册中心上。另一方(消费者|服务提供者) ,以该别名的方式去注册中心上获取到实际的服务通讯地址,然后再实现本地RPC调用RPC远程调用框架核心设计思想:在于注册中心,因为使用注册中心管理每个服务与服务之间的一个依赖关系(服务治理概念)。在任何rpc远程框架中, 都会有一个注册中心(存放服务 地址相关信息(接口地址))
Eureka Server
Eureka Server提供服务注册服务各个微服务节点通过配置启动后,会在EurekaServer中进行注册,这样EurekaServer中的服务注册表中将会存储所有可用服务节的信息,服务节点的信息可以在界面中直观看到。
EurekaClient
EurekaClient通过注册中心进行访问,是一个Java客户端,用于简化Eureka Server的交互,客户端同时也具备一个内置的、 使用轮询(round-robin)负载算法的负载均衡器。在应用启动后,将会向Eureka Server发送心跳(默认周期为30秒。 如果Eureka Server在多个心跳周期内没有接收到某个节点的心跳,EurekaServer将会从服务注册表中把这个服务节点移除(默认90秒)
cloud-eureka-server8000
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| server:
port: 8000
eureka:
instance:
hostname: localhost
client:
register-with-eureka: false
fetch-registry: false
service-url:
defaultZone: http://localhost:8761/eureka/
spring:
application:
name: eureka-server
|
Eureka集群
1先启动eureka注册中心
2启动服务提供者paymen支付服务
3支付服务启动后会把自身信息(比如服务地址以别名方式注
册进eureka)
4消费者order服务在需要调用接口时,使用服务别名去注册
中心获取实际的RPC远程调用地址
5消费者获得调用地址后,底层实际是利用HttpClient技术
,实现远程调用
6消费者获得服务地址后会缓存在本地jvm内存中,默认每间
隔30秒更新一次服务调用地址
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
server:
port: 7000
eureka:
instance:
hostname: eureka7000.com
client:
register-with-eureka: false
fetch-registry: false
service-url:
defaultZone: http://eureka8000.com:8000/eureka/
spring:
application:
name: eureka-server
|
:star:默认情况下,Eureka集群之间会自动同步复制,也就是只需要注册一个注册中心即可。
![image-20200712110648512]()
服务调用
修改Order模块控制层
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| @RestController
@Slf4j
public class OrderController {
public static final String PAYMENT_URL = "http://CLOUD-PAYMENT-SERVICE";
@Resource
private RestTemplate restTemplate;
@GetMapping("/consumer/payment/create")
public CommonResult<Payment> create(Payment payment){
return restTemplate.postForObject(PAYMENT_URL+
"/payment/create", payment, CommonResult.class);
}
@GetMapping("/consumer/payment/get/{id}")
public CommonResult<Payment> getPayment(@PathVariable("id") Long id){
return restTemplate.getForObject(PAYMENT_URL+"/payment/get/"+id,
CommonResult.class);
}
}
|
添加负载均衡
1
2
3
4
5
6
7
8
9
| @Configuration
public class ApplicationContextConfig {
@Bean
@LoadBalanced
public RestTemplate getRestTemplate(){
return new RestTemplate();
}
}
|
Eureka自我保护机制
默认情况下,如果EurekaServer在一定时间内没有接收到某 个微服务实例的心跳,EurekaServer将 会注销该实例(默认90秒)。但是当网络分区故障发生(延时、卡顿、拥挤)时,微服务与EurekaServer之间无法正常通信,以上行为可能变得非常危险了一因为微服务本身其实是健康的,此时本不应该注销这个微服务。Eureka通过”自我保护模式”来解决这个问题一-当EurekaServer节 点在短时间内丢失过多客户端时(可能发生了网络分区故障) , 那么这个节点就会进入自我保护模式。
1
2
3
4
5
| instance :
lease-renewal-interval-in-seconds: 1
lease-expiration-duration-in-seconds: 2
|
使用Zookeeper替代Eureka
POM导包
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| <dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zookeeper-discovery</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-autoconfigure</artifactId>
<version>2.2.2.RELEASE</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.4</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.tosang</groupId>
<artifactId>cloud-api-commons</artifactId>
<version>1.0-SNAPSHOT</version>
</dependency>
</dependencies>
|
YML配置
1
2
3
4
5
6
7
8
9
10
|
server:
port: 8004
spring:
application:
name: cloud-provider-payment
cloud:
zookeeper :
connect-string: 192.168.2.106:2181
|
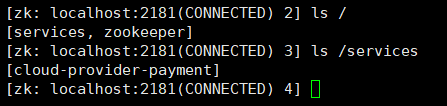
启动项目后检测是否注册进zk,可以看到cloud-provider-payment入驻,通过get可以获取连接详情
![image-20200714160236259]()
比较三个注册中心与CAP原则
最多只能同时较好的满足两个。
CAP理论的核心是: 一个分布式系统不可能同时很好的满足致性, 可用性和分区容错性这三个需求,
因此,根据CAP原理将NoSQL数据库分成了满足CA原则、满足CP原则和满足AP原则三大类:
CA-单点集群,满足一致性,可用性的系统,通常在可扩展性上不太强大。
CP-满足一致性,分区容忍必的系统,通常性能不是特别高。
AP-满足可用性,分区容忍性的系统,通常可能对一致性要求低一些。
AP --- Eureka
CP --- Zookeeper/Consul
Ribbon
Spring Cloud Ribbon是基于Netlix Ribbon实现的一套客户端负载均衡的工具。Ribbon属于进程内LB。
新版netflix的eureka集成了Ribbon
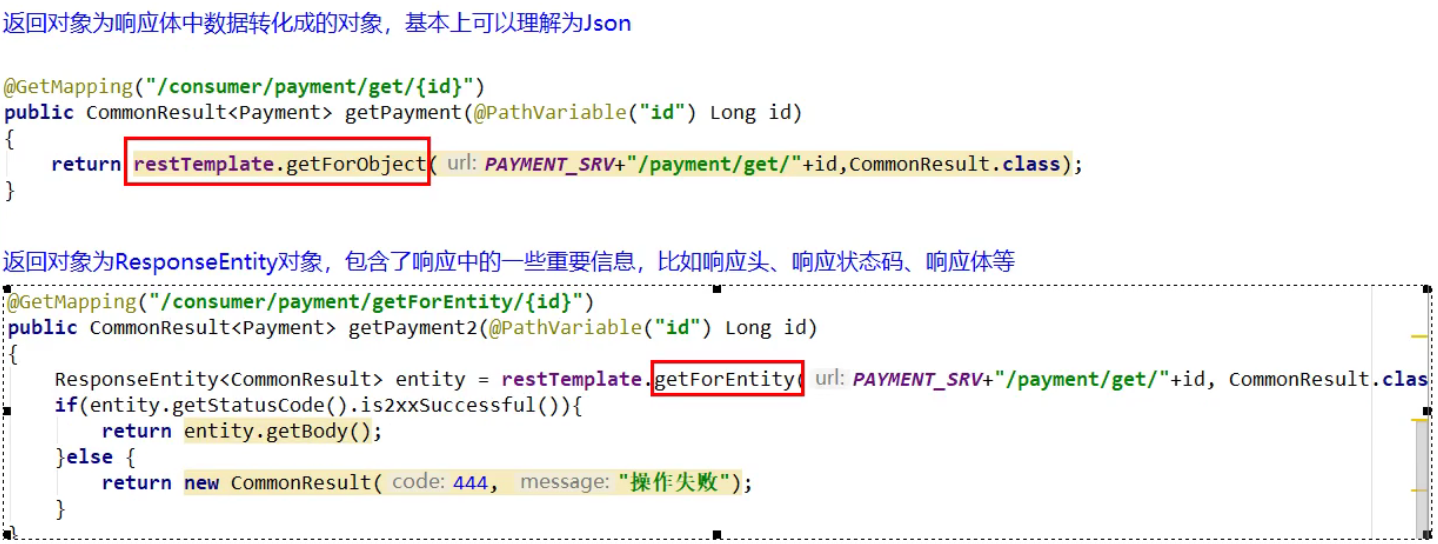
RestTemplate补充
![image-20200714174838728]()
Ribbon负载规则替换
1
2
3
4
5
6
7
8
9
|
@Configuration
public class MySelfRule {
@Bean
public IRule myRule(){
return new RandomRule();
}
}
|
主启动类添加RibbonClient
1
2
3
4
5
6
7
8
| @SpringBootApplication
@EnableEurekaClient
@RibbonClient(name = "CLOUD-PAYMENT-SERVICE", configuration = MySelfRule.class)
public class OrderMain80 {
public static void main(String[] args) {
SpringApplication.run(OrderMain80.class, args);
}
}
|
Ribbon的轮询算法底层使用了:CAS+自旋锁
CAS(Compare-and-Swap),即比较并替换,java并发包中许多Atomic的类的底层原理都是CAS。
它的功能是判断内存中某个地址的值是否为预期值,如果是就改变成新值,整个过程具有原子性。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
public class CASDemo {
public static void main(String[] args) {
AtomicInteger atomicInteger = new AtomicInteger(5);
System.out.println("预期值:5,当前值:"+atomicInteger);
System.out.println("是否设置成功:"+atomicInteger.compareAndSet(5, 10));
System.out.println("预期值:5,当前值:"+atomicInteger);
System.out.println("是否设置成功:"+atomicInteger.compareAndSet(5, 15));
System.out.println("当前值:"+atomicInteger);
}
}
预期值:5,当前值:5
是否设置成功:true
预期值:5,当前值:10
是否设置成功:false
当前值:10
|
所谓自旋:即循环进行CAS
手写轮询算法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| @Component
public class MyLb implements LoadBalancer{
private AtomicInteger atomicInteger = new AtomicInteger(0);
public final int getAndIncrement(){
int current;
int next;
do{
current = this.atomicInteger.get();
next = current >= Integer.MAX_VALUE ? 0 : current + 1;
}while (!this.atomicInteger.compareAndSet(current, next));
System.out.println("*****第几次访问,次数为next = "+next);
return next;
}
@Override
public ServiceInstance instances(List<ServiceInstance> serviceInstances) {
int index = getAndIncrement() % serviceInstances.size();
return serviceInstances.get(index);
}
}
|
OpenFeign
Feign是一个声明式WebService客户端。 使佣Feign能让编写Web Service客户端更加简单。它的使用方法是定义一个服务接口然后在上面添加注解。Feign也支持可拔插式的编码器和解码器。Spring Cloud对Feign进行了封装,使其支持了Spring MVC标准注解和HttpMessageConverters. Feign可以与Eureka和Ribbon组合使用以支持负载均衡。类似于dubbo。OpenFeign是支持SpringMVC的改进
POM
1
2
3
4
5
|
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>
|
YML
1
2
3
4
5
6
7
8
| server:
port: 80
eureka:
client:
register-with-eureka: false
service-url:
defaultZone: http://eureka7001.com:7001/eureka/
|
主启动类
1
2
3
4
5
6
7
| @SpringBootApplication
@EnableFeignClients
public class OrderFeignMain80 {
public static void main(String[] args) {
SpringApplication.run(OrderFeignMain80.class, args);
}
}
|
接口
1
2
3
4
5
6
| @Component
@FeignClient(value = "CLOUD-PAYMENT-SERVICE")
public interface PaymentFeignService {
@GetMapping(value= "/payment/get/{id}")
public CommonResult getPaymentById(@PathVariable("id")Long id);
}
|
OpenFeign超时控制
默认Feign客户端只等待一秒钟, 但是服务端处理需要超过1秒钟,导致Feign客户端不想等待了, 直接返回报错。为了避免这样的情况,有时候我们需要设置Feign客户端的超时控制。
1
2
3
4
5
6
|
ribbon:
ReadTimeout: 5000
connectTimeout: 5000
|
OpenFeign日志级别
NONE:默认的,不显示任何日志;
BASIC: 仅记录请求方法、URL、 响应状态码及执行时间;
HEADERS:除了BASIC中定义的信息之外,还有请求和响应的头信息; .
FULL: 除了HEADERS中定义的信息之外,还有请求和响应的正文及元数据。
编写config.FeignConfig
1
2
3
4
5
6
7
| @Configuration
public class FeignConfig{
@Bean
Logger.Level feignLoggerLevel(){
return Logger.Level.FULL;
}
}
|
YML
1
2
3
4
| logging:
level:
com.atguigu.springcloud.service.PaymentFeignService: debug
|
Hystrix
Hystrix断路器
多个微服务之间调用的时候,假设微服务A调用微服务B和微服务C,微服务B和微服务C又调用其它的微服务,这就是所谓的”扇出”。如果扇出的链路上某个微服务的调用响应时间过长或者不可用,对微服务A的调用就会占用越来越多的系统资源,进而引起系统崩溃,所
谓的“雪崩效应”.
对于高流量的应用来说,单一的后端依赖可能会导致所有服务器 上的所有资源都在几秒钟内饱和。比失败更糟糕的是,这些应用程序还
可能导致服务之间的延迟增加,备份队列,线程和其他系统资源紧张,导致整个系统发生更多的级联故障。这些都表示需要对故障和延迟进行隔离和管理,以便单个依赖关系的失败,不能取消整个应用程序或系统。
Hystrix是一个用于处理分布式系统的延迟和容错的开源库, 在分布式系统里,许多依赖不可避免的会调用失败,比如超时、异常等,Hystrix能够保证在一个依赖出问题的情况下, 不会导致整体服务失败,避免级联故障,以提高分布式系统的弹性。
“断路器”本身是一 种开关装置,当某个服务单元发生故障之后,通过断路器的故障监控(类似熔断保险丝) ,向调用方返回一个符合预期的、可处理的备选响应(FallBack) ,而不是长时间的等待或者抛出调用方无法处理的异常,这样就保证了服务调用方的线程不会被长时间、不必要地占用,从而避免了故障在分布式系统中的蔓延,乃至雪崩。
服务降级、熔断和限流
降级相当于兜底的方案,而不是直接返回错误;熔断相当于保险丝;限流一般用在高并发和秒杀场景
使用
POM
1
2
3
4
| <dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix</artifactId>
</dependency>
|
YML
1
2
3
4
5
6
7
8
9
10
11
12
13
| server:
port: 8001
spring:
application:
name: cloud-provider-hystrix-payment
eureka:
client:
register-with-eureka: true
fetch-registry: true
service-url:
defaultZone: http://eureka7001:7001/eureka
|
JMeter测压
100 QPS 循环200次,会出现明显延迟
服务降级
检测到异常会调用fallback方法;服务降级一般加在客户端
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
| @Service
public class PaymentService {
public String paymentInfo_ok(Integer id){
return "线程池: "
+ Thread.currentThread().getName()
+ "paymentInfo_ok, id"
+ id
+ "\t"
+ "hhhhhh";
}
@HystrixCommand(fallbackMethod = "paymentInfo_TimeOutHandler", commandProperties = {
@HystrixProperty(name = "execution.isolation.thread.timeoutInMilliseconds", value = "3000")
})
public String paymentInfo_TimeOut(Integer id){
try{
TimeUnit.SECONDS.sleep(5);
} catch (InterruptedException e) {
e.printStackTrace();
}
return "线程池: "
+ Thread.currentThread().getName()
+ "paymentInfo_TimeOut, id"
+ id
+ "\t"
+ "耗时3秒";
}
public String paymentInfo_TimeOutHandler(Integer id){
try{
TimeUnit.SECONDS.sleep(3);
} catch (InterruptedException e) {
e.printStackTrace();
}
return "线程池: "
+ Thread.currentThread().getName()
+ "paymentInfo_TimeOutHandler, id"
+ id
+ "\t"
+ "系统繁忙,请稍后再试";
}
}
|
当有多个方法需要进行降级处理时,使用@DefaultProperties注解在类上,指明默认的奖及策略,此时使用@HystrixCommand注解的方法会调用该默认策略。
Feign Fallback
根据cloud-consumer-feign-hystrix-order80已经有的PaymentHystrixService接口,重新新建一个类(PaymentFallbackService)实现该接口, 统一为接口里面的方法进行异常处理PaymentFallbackService类实现PaymentFeignClientService接口。
:star:这种思路相当于针对service接口层进行集中处理降级,由于service层接口使用Feign调用微服务,只需要编写集成这些接口的降级处理类,并绑定到该接口上即可。
1
2
3
4
5
6
7
8
9
| @Component
@FeignClient(value = "CLOUD-PROVIDER-HYSTRIX-PAYMENT" ,fallback = PaymentFallbackservice.class )
public interface PaymentHystrixService
{
@GetMapping("/payment/hystrix/ok/{id}")
public string paymentInfo_ OK (@PathVariable("id") Integer id);
@GetMapping(" /payment/hystrix/timeout/{id}" )
public string payment Info_ TimeOut(@PathVariable("id") Integer id);
|
1
2
3
4
5
6
7
8
9
10
| @Component
public class PaymentFallbackService implements PaymentHystrixService
{
@Override
public string paymentInfo_OK(Integer id){
return "-----PaymentFallbackService fa1l back-paymentInfo_ OK ,0(τ_ π)o";
@override
public string paymentInfo_Timeout(Integer id)
return "-----PaymentFallbackservice fall back-paymentInfo_ TimeOut ,0(τ_ .π)o";
}
|
熔断机制
熔断机制是应对雪崩效应的一种微服务链路保护机制。当扇出链路的某个微服务出错不可用或者响应时间太长时,会进行服务的降级,进而熔断该节点微服务的调用,快速返回错误的响应信息。当检测到该节点微服务调用响应正常后,恢复调用链路。在Spring Cloud框架里,熔断机制通过Hystrix实现。Hystrix会监控微服务间调用的状况,当失败的调用到一定阈值,缺省是5秒内20次调用失败,就会启动熔断机制。熔断机制的注解是@HystrixCommand.
熔断案例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
@HystrixCommand( fallbackMethod = "paymentCircuitBreaker_fallback" , commandproperties = {
@HystrixProperty(name = "circuitBreaker.enabled" ,value = "true"),
@HystrixProperty(name = "circuitBreaker.requestVolumeThreshold" ,value = "10"),
@HystrixProperty(name = "circuitBreaker.sleepwindowInMilliseconds" ,value = "10000"),
@HystrixProperty(name = "circuitBreaker.errorThresholdPercentage" ,value = "60"),
})
public string paymentCircuitBreaker (@Pathvariable("id") Integer id){
if(id < 0)
throw new RuntimeException(******id 不能负数");
String serialNumber = Idutil.simpleUUID();
return Thread.current.Thread().getName()+"\t"+"调用成功,流水号:"+ serialNumber;
public String paymentCircuitBreaker_fallback(@PathVariable("id") Integer id){
return "id不能负数,请稍后再试,/(ToT)/~~ id:"+id;
}
|
1
2
| graph LR
A[熔断] -->|触发| B[降级]
|
服务网关
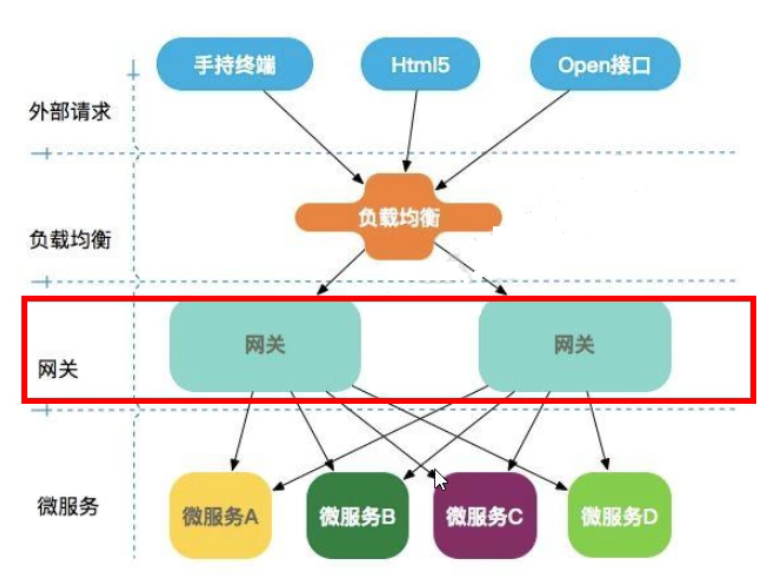
GatWay
SpringCloud Gateway作为Spring Cloud生态系统中的网关,目标是替代Zuul,在Spring Cloud 2.0以上版本中,没有对新版本的Zuu1 2.上最新高性能版本进行集成,仍然还是使用的Zuul 1.x非Reactor模式的老版本。而为了提升网关的性能,SpringCloud Gateway是基于WebFlux框架实现的,而WebFlux框架底层则使用了高性能的Reactor模式通信框架Netty。
![image-20200718090110820]()
Route
路由是构建网关的基本模块,它由ID,目标URI, 一系列的断言和过滤器组成,如果断言为true则匹配该路由
Predicate(断言)
开发人员可以匹配HTTP请求中的所有内容(例如请求头或请求参数), 如果请求与断言相匹配则进行路由
Filter
指的是Spring框架中GatewayFilter的实例,使用过滤器,可以在请求被路由前或者之后对请求进行修改
:star:Filter在”pre” 类型的过滤器可以做参数校验、权限校验、流量监控、日志输出、协议转换等,在”post” 类型的过滤器中可以做响应内容、响应头的修改,旧志的输出,流量监控等有着非常重要的作用。
搭建
POM,注意要排除web依赖
1
2
3
4
5
|
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
</dependency>
|
YML,注意- Path的P是大写
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| server:
port: 9527
spring:
application:
name: cloud-gateway
cloud:
gateway:
routes:
- id: payment_routh
uri: http://localhost:8001
predicates:
- Path=/payment/get/**
- id: payment_routh2
uri: http://localhost:8001
predicates:
- Path=/payment/lb/**
eureka:
instance:
hostname: cloud-gateway-service
client:
register-with-eureka: true
fetch-registry: true
service-url:
defaultZone: http://eureka7001.com:7001/eureka
|
:star: 实际场景下,网关将指定端口拦截并路由到指定ip+内部端口,此内部端口会添加防火墙
硬编码写法
1
2
3
4
5
6
7
8
9
10
| @Configuration
public class GatewayConfig
@Bean
public RouteLocator customRouteLocator( RouteLocatorBuilder routeLocatorBuilder)
RouteLocatorBuilder.Builder routes = routeLocatorBuilder.routes();
routes.route("path_route_atguigu", r -> r.path("/guonei" ).uri("http://news . baidu. com/ guonei")).build();
return routes.build();
}
}
|
配置动态路由
负载均衡使用的Ribbon
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| server:
port: 9527
spring:
application:
name: cloud-gateway
cloud:
gateway:
routes:
- id: payment_routh
uri: lb://cloud-payment-service
predicates:
- Path=/payment/get/**
discovery:
locator:
enabled: true
eureka:
instance:
hostname: cloud-gateway-service
client:
register-with-eureka: true
fetch-registry: true
service-url:
defaultZone: http://eureka7001.com:7001/eureka
|
常用的predicates
GateWay有多种断言,包含对时间、Cookie、Header、Host、Path、Query等多种条件的匹配,参数为名称+正则表达式
Filter的使用:主要是自定义过滤器
路由过滤器可用于修改进入的HTTP请求和返回的HTTP响应,路由过滤器只能指定路由进行使用。Spring Cloud Gateway内置了多种路由过滤器,他们都由GatewayFilter的工厂类来产生
过滤器类似于Spring的拦截器可以进行生成日志、鉴权等工作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
| package com.tosang.springcloud.config;
import lombok.extern.slf4j.Slf4j;
import org.springframework.cloud.gateway.filter.GatewayFilterChain;
import org.springframework.cloud.gateway.filter.GlobalFilter;
import org.springframework.core.Ordered;
import org.springframework.http.HttpStatus;
import org.springframework.stereotype.Component;
import org.springframework.web.server.ServerWebExchange;
import reactor.core.publisher.Mono;
import java.util.Date;
@Component
@Slf4j
public class MyLogGateWayFilter implements GlobalFilter, Ordered {
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
log.info("************come in MyLogGateWayFilter: " + new Date());
String uname = exchange.getRequest().getQueryParams().getFirst("uname");
if(uname == null){
log.info("************用户非法");
exchange.getResponse().setStatusCode(HttpStatus.NOT_ACCEPTABLE);
return exchange.getResponse().setComplete();
}
return null;
}
@Override
public int getOrder() {
return 0;
}
}
|
Config
分布式微服务配置中心
POM
1
2
3
4
5
|
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-config-server</artifactId>
</dependency>
|
YML
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| server:
port: 3344
spring:
application:
name: cloud-config-center
cloud:
config:
server:
git:
uri: xxxxxxxxxx
search-paths:
- springcloud-config
username: xxxx
password: xxxxx
default-label: master
eureka:
client:
service-url:
defaultZone: http://localhost:7001/eureka
|
主启动类添加注解
1
2
3
4
5
6
7
8
| @SpringBootApplication
@EnableEurekaClient
@EnableConfigServer
public class ConfigCenterMain3344 {
public static void main(String[] args) {
SpringApplication.run(ConfigCenterMain3344.class, args);
}
}
|
访问格式 1
http://loacalhost:port/{label}/{application}-{profile}.yml
其中{label}代表分支,可以省略,默认是master分支
{application}-{profile}.yml是文件名
{profile}一般是指明环境:开发,测试,发布等
访问格式 2
逆向url访问,得到的是json字符串
客户端配置与测试
POM文件引入客户端
1
2
3
4
5
|
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-config</artifactId>
</dependency>
|
bootstrap.yml加载外部源
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| server:
port: 3355
spring:
application:
name: config-client
cloud:
config:
label: master
name: config
profile: dev
uri: http://localhost:3344
eureka:
client:
service-url:
defaultZone: http://localhost:7001/eureka
|
控制层注入配置
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| package com.tosang.springcloud.controller;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class ConfigClientController {
@Value("{spring.application.name}")
private String name;
@GetMapping("/configInfo")
public String getName(){
return name;
}
}
|
Config动态刷新
默认情况下客户端读取的数据不会随着github仓库动态刷新,每次都需要重启客户端,很烦:cry:
解决办法——>手动刷新
1
2
3
4
5
6
7
8
9
10
11
12
13
|
management:
endpoints:
web:
exposure:
include: "*"
|
修改完之后还需要post命令请求刷新:curl -X POST “http://localhost/actuator/refresh"
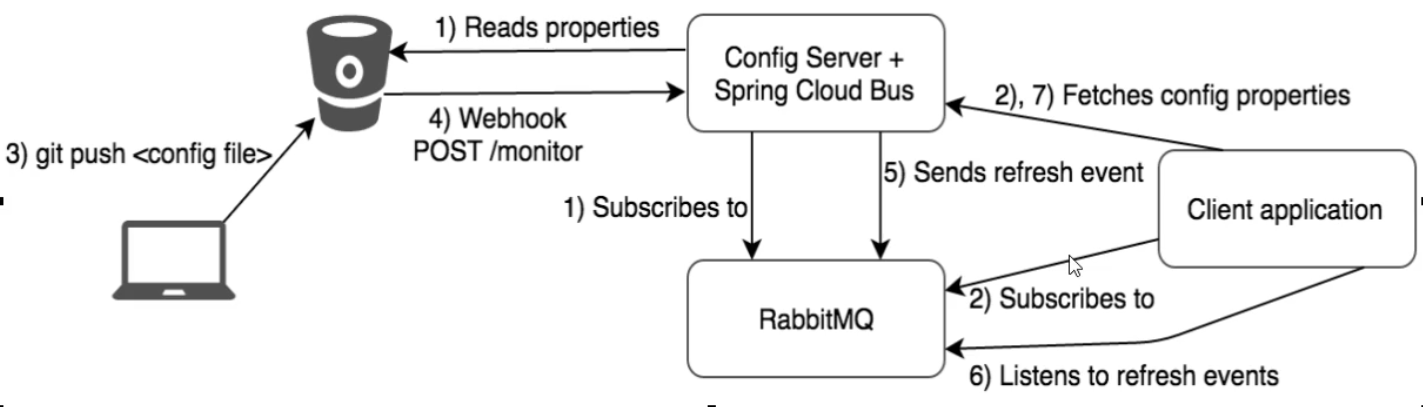
Bus消息总线
SpringCloud Bus配合SpringCloud Config使用可以实现配置的动态刷新。
:star:利用消息总线触发一个服务端ContigServer的/bus/refresh端点,通过rabbitmq广播刷新所有客户端的配置。
:heavy_exclamation_mark:但是一般不加在config客户端,因为从设计思想上考虑,微服务负责的功能应该单一,应该减少对微服务客户端的侵入。
![image-20200720102146254]()
SpringCloud Stream
官方定义Spring Cloud Stream是一个构建消息驱动微服务的框架。应用程序通过inputs或者outputs来与Spring Cloud Streamtlbinder对象交互。通过我们配置来binding(绑定) ,而Spring Cloud Stream的binder对象负责与消息中间件交互。所以,我们只需要搞清楚如何与Spring Cloud Stream交互就可以方便使用消息驱动的方式。通过使用Spring Integration来连接消息代理中间件以实现消息事件驱动。Spring Cloud Stream为一些供应商的消息中间件产品提供了个性化的自动化配置实现,引用了发布-订阅、消费组、分区的三个核心概念。
目前仅支持RabbitMQ、Kafka.
Binder:很方便的连接中间件,屏蔽差异
Channel:队列Queue的一种抽象
Source和Sink:消息输入与输出
生产者&消费者
POM
1
2
3
4
| <dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-stream-rabbit</artifactId>
</dependency>
|
YML
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
| server:
port: 8801
spring:
application:
name: cloud-stream-provider
cloud:
stream:
bindings:
output:
destination: studyExchange
content-type: application/json
binder: defaultRabbit
binders:
defaultRabbit:
type: rabbit
environment:
spring:
rabbitmq:
host: 192.168.2.106
port: 5672
username: guest
password: guest
eureka:
client:
register-with-eureka: true
fetch-registry: true
service-url:
defaultZone: http:localhost:7001/eureka/
instance:
lease-renewal-interval-in-seconds: 2
lease-expiration-duration-in-seconds: 5
instance-id: send-8801.com
prefer-ip-address: true
|
发送服务
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| @EnableBinding(Source.class) //定义消息的推送管道:生产方使用source
public class IMessageProviderImpl implements IMessageProvider
{
@Resource
private MessageChannel output;
@Override
public String send() {
String serial = UUID.randomUUID().toString();
output.send(MessageBuilder.withPayload(serial).build());
System.out.println("******serial: " + serial);
return null;
}
}
|
重复消费问题
如果同一个订单被两个服务获取到,那么就会造成数据错误,Stream中使用group解决。同样一个group内多个消费者是竞争关系。
Sleuth
在微服务框架中,一个由客户端发起的请求在后端系统中会经过多个不同的的服务节点调用来协同产生最后的请求结果,每一个前段请求都会彩成一条复杂的分布式服务调用链路,链路中的任何一环出现高延时或错误都会引起整个请求最后的失败。Sleuth是一款分布式链路跟踪组件
POM
1
2
3
4
5
|
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
|
YML
1
2
3
4
5
| zipkin:
base-url: http://localhost:9411
sleuth:
sampler:
probability: 1
|
注意:Sleuth在调用链上每个微服务节点的配置完全相同,下面开启监控即可查看调用链。
ref: https://www.jianshu.com/p/f177a5e2917f
SpringCloud Alibaba
Nacos–服务注册配置中心
更易于构建云原生应用的动态服务发现、配置管理和服务管理平台。
Nacos: Dynamic Naming and Configuration Service
Nacos就是注册中心+配置中心的组合
- 替代Eureka做服务注册中心
- 替代Config做服务配置中心
下载并体验:https://github.com/alibaba/nacos/releases
服务注册
POM
1
2
3
4
| <dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
|
YML/properties
1
2
3
4
| server.port=8081
spring.application.name=nacos-provider
spring.cloud.nacos.discovery.server-addr=127.0.0.1:8848
management.endpoints.web.exposure.include=*
|
使用IDEA的Copy Configure功能可以直接复制一份微服务,不用重新编写,只需要在VM OPTION那一栏填写指定端口:-Dserver.port = 9011
CAP
Nacos支持AP和CP模式切换,C是所有节点看到的数据是一致的;而A的定义是所有的请求都会收到响应。P是多备份。
配置中心
POM
1
2
3
4
5
6
7
8
9
10
11
|
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>
|
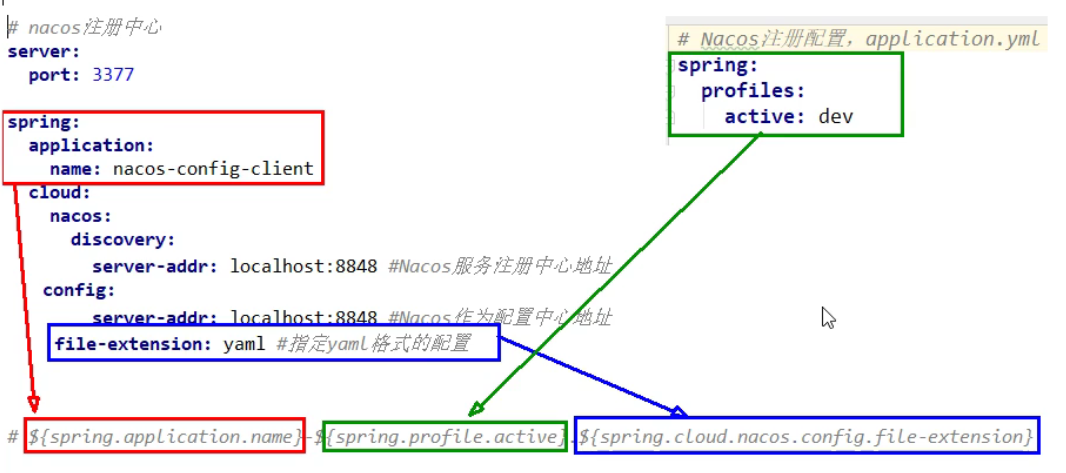
bootstrap.yml
1
2
3
4
5
6
7
8
9
10
11
12
13
|
server:
port: 3377
spring:
application:
name: nacos-config-client
cloud:
nacos:
discovery:
server-addr: localhost:8848
config:
server-addr: localhost:8848
file-extension: yaml
|
application.yml
1
2
3
| spring:
profiles:
active: dev
|
Nacos配置中心格式
![image-20200723095951047]()
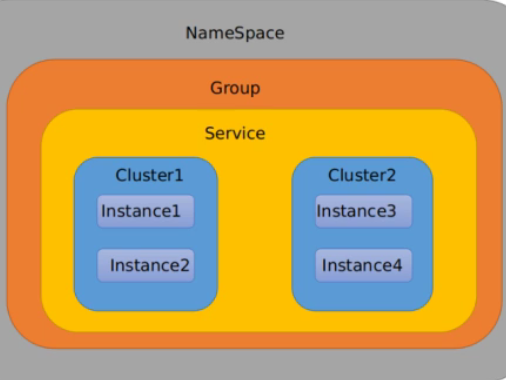
Nacos分类配置
![image-20200723100728942]()
Nacos默认的命名空间是public, Namespace主要用来实现隔离。比防说我们现在有三个环境:开发、测试、产环境,我们就可以创建三个Namespace,不同的Namespace之间是隔离的。
Group默认是DEFAULT_ GROUP, Group可以把不同的微服务划分到同一个分组里面去
Service就是微服务;一个Service可以包含多个Cluster (集群) ,Nacos默认Cluster是DEFAULT, Cluster是对指定微服务的一个虚拟划分。
:star:比如说为了容灾,将Service微服务分别部署在了杭州机房和广州机房,这时就可以给杭州机房的Service微服务起一 个集群名称(HZ),给广州机房的Service微服务起一 个集群名称(GZ) ,还可以尽量让同一个机房的微服务互相调用,以提升性能。
最后是Instance,就是微服务的实例。
Nacos集群和持久化配置
- 推荐使用docker安装集群,参考https://github.com/nacos-group/nacos-docker
- 安装后会有三个nacos集群,一个mysql。
- Nacos集群一般使用
Nginx来反向代理实现负载均衡。
docker ps查看。
Sentinel实现熔断与限流
Sentinel: 分布式系统的流量防卫兵,参考Github
Sentinel 分为两个部分:
- 核心库(Java 客户端)不依赖任何框架/库,能够运行于所有 Java 运行时环境,同时对 Dubbo / Spring Cloud 等框架也有较好的支持。
- 控制台(Dashboard)基于 Spring Boot 开发,打包后可以直接运行,不需要额外的 Tomcat 等应用容器
QPS和线程数控制
Sentinel流控-关联
即/A资源关联/B资源,当/B资源受到压力,对/A资源进行流量控制
Sentinel流控-预热
Warm Up(RuleConstant.CONTROL_BEHAVIOR_WARM_UP)方式,即预热/冷启动方式。当系统长期处于低水位的情况下,当流量突然增加时,直接把系统拉升到高水位可能瞬间把系统压垮。通过”冷启动”,让通过的流量缓慢增加,在一定时间内逐渐增加到阈值上限,给冷系统一个预热的时间,避免冷系统被压垮。
默认 coldFactor 为 3,即请求 QPS 从 threshold / 3 开始,经预热时长逐渐升至设定的 QPS 阈值。
Sentinel流控-排队等待
匀速排队(RuleConstant.CONTROL_BEHAVIOR_RATE_LIMITER)方式会严格控制请求通过的间隔时间,也即是让请求以均匀的速度通过,对应的是漏桶算法。
Sentinel流控-降级
Sentinel 熔断降级会在调用链路中某个资源出现不稳定状态时(例如调用超时或异常比例升高),对这个资源的调用进行限制,让请求快速失败,避免影响到其它的资源而导致级联错误。当资源被降级后,在接下来的降级时间窗口之内,对该资源的调用都自动熔断
- 平均响应时间 (
DEGRADE_GRADE_RT):当 1s 内持续进入 N 个请求,对应时刻的平均响应时间(秒级)均超过阈值(count,以 ms 为单位),那么在接下的时间窗口(DegradeRule 中的 timeWindow,以 s 为单位)之内,对这个方法的调用都会自动地熔断(抛出 DegradeException)。注意 Sentinel 默认统计的 RT 上限是 4900 ms,超出此阈值的都会算作 4900 ms,若需要变更此上限可以通过启动配置项 -Dcsp.sentinel.statistic.max.rt=xxx 来配置。 - 异常比例 (
DEGRADE_GRADE_EXCEPTION_RATIO):当资源的每秒请求量 >= N(可配置),并且每秒异常总数占通过量的比值超过阈值(DegradeRule 中的 count)之后,资源进入降级状态,即在接下的时间窗口(DegradeRule 中的 timeWindow,以 s 为单位)之内,对这个方法的调用都会自动地返回。异常比率的阈值范围是 [0.0, 1.0],代表 0% - 100%。 - 异常数 (
DEGRADE_GRADE_EXCEPTION_COUNT):当资源近 1 分钟的异常数目超过阈值之后会进行熔断。注意由于统计时间窗口是分钟级别的,若 timeWindow 小于 60s,则结束熔断状态后仍可能再进入熔断状态。
Sentinel热点key
何为热点?热点即经常访问的数据。很多时候我们希望统计某个热点数据中访问频次最高的 Top K 数据,并对其访问进行限制。比如:
- 商品 ID 为参数,统计一段时间内最常购买的商品 ID 并进行限制
- 用户 ID 为参数,针对一段时间内频繁访问的用户 ID 进行限制
热点参数限流会统计传入参数中的热点参数,并根据配置的限流阈值与模式,对包含热点参数的资源调用进行限流。热点参数限流可以看做是一种特殊的流量控制,仅对包含热点参数的资源调用生效。
Sentinel 利用 LRU 策略统计最近最常访问的热点参数,结合令牌桶算法来进行参数级别的流控。热点参数限流支持集群模式。
Sentinel系统规则
Sentinel 系统自适应限流从整体维度对应用入口流量进行控制,结合应用的 Load、CPU 使用率、总体平均 RT、入口 QPS 和并发线程数等几个维度的监控指标,通过自适应的流控策略,让系统的入口流量和系统的负载达到一个平衡,让系统尽可能跑在最大吞吐量的同时保证系统整体的稳定性
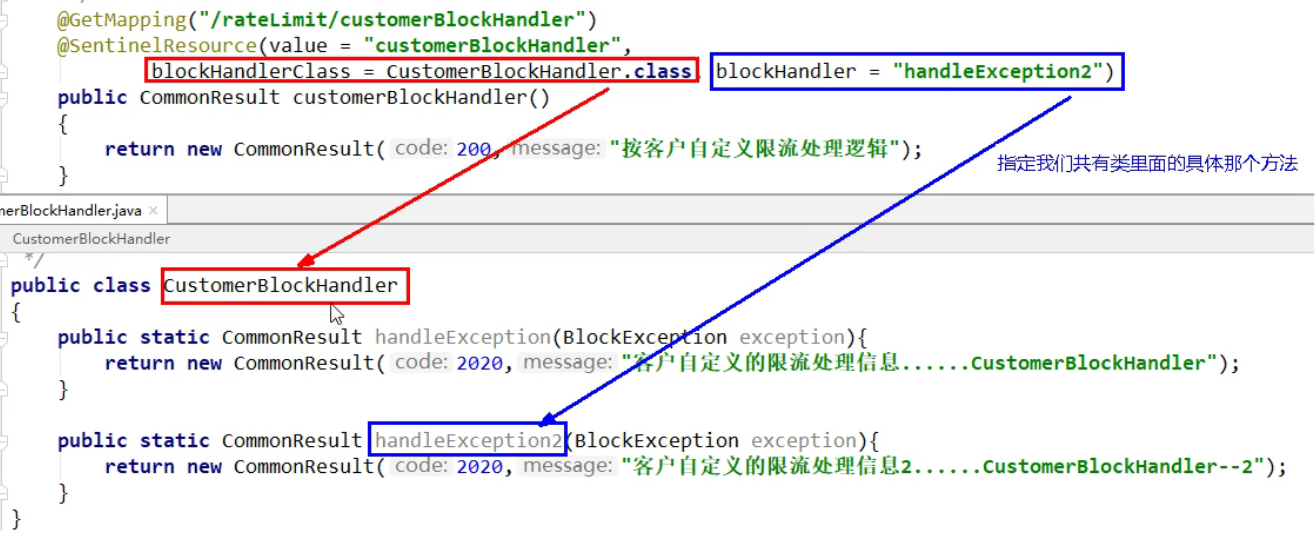
@SentinelResource自定义配置
![image-20200724110933099]()
- fallback管理内部异常
- blockhandler管理熔断限流配置异常(外部)
Sentinel持久化规则
POM
1
2
3
4
5
|
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-datasource-nacos</artifactId>
</dependency>
|
YML
1
2
3
4
5
6
7
8
| datasource :
ds1:
nacos:
server-addr: localhost:8848
dataId: Cloudalibaba -sentinel-service
groupId: DEFAULT_GROUP
data-type: json
rule -type: flow
|
去Nacos控制台创建json配置文件
1
2
3
4
5
6
7
8
9
10
11
| [
{
"resource": "/rateLimit/byUrl",
"limitApp": "default",
"grade": 1,
"count": 1,
"strategy": 0,
"controlBehavior": 0,
"clusterMode": false
}
]
|
Senta处理分布式事务
官网
TC (Transaction Coordinator) - 事务协调者
维护全局和分支事务的状态,驱动全局事务提交或回滚。
TM (Transaction Manager) - 事务管理器
定义全局事务的范围:开始全局事务、提交或回滚全局事务。
RM (Resource Manager) - 资源管理器
管理分支事务处理的资源,与TC交谈以注册分支事务和报告分支事务的状态,并驱动分支事务提交或回滚。
Senta的AT模式是来自于两阶段过程的改进